pH Test : Leading the way
A dedicated, cross-functional team of experts is continuously working towards improving the pH Test. The R&D spend on pH Test development is in excess of 30% of eLitmus revenue.
- Path breaking approach to increase test validity and reliability
eLitmus uses on-the-job performance feedback to continuously improve the test validity. A section of eLitmus customers share the non-soft skill appraisal of the selected candidates with eLitmus. On the reliability front, typical company tests have questions randomly jumbled to generate multiple sets of question paper. Very basic research establishes that the performance of a test-taker can vary across sets when questions are jumbled randomly. Theoretical approaches like test re-test reliability,etc have also been found wanting in completely randomly generated tests. Apart from employing such theoretical approaches, eLitmus also uses a proprietary statistical measure which draws significant inputs from on job performance as well.
- Thought leadership
In Jan 2006, eLitmus advocated that time-challenged approach was not the best measure given the change in India’s education system. It moved to a content challenged test and strongly advocated the same on multiple forums. The second big thing eLitmus advocated was that classical English (including rarely used vocabulary words) was a wrong measure. At the work place, day-to-day communication had to be effective. It was evident given the performance feedback shared with eLitmus. People with high scores in verbal section were rated poor team players and communicators. eLitmus stand stood vindicated when CAT, an admission test to best top B Schools in India implemented both the philosophies. In Nov 2006, CAT was no longer time challenged as it had fewer questions than ever historically. In Nov 2008, CAT had 40 question in Verbal in contrast to 25 each in Quantitative and Problem Solving sections. It was evident that the difficulty level of verbal question was easy and hence less time per question was made available to test takers.
- Minimized knowledge component
All necessary formulae are provided in the question paper. Additionally our team continuously tracks the tricks being taught in the coaching institutes. The idea is to minimize the advantage to test takers who have undergone “excessive” preparation without actually improving their fundamental abilities.
- Pen and paper test (originally Online)
There are a plethora of online tests leading to a certification offered by the best names in the technology industry. Why is it that most successful takers of such tests fail to impress recruiters anymore? A basic feature of online tests is a random pool of questions selected from a large pool of questions. This creates a threat to test reliability (in lay-man's terms, two instances of a test being of equal difficulty). This can be achieved with a high degree of accuracy only if there is over standardization in selecting questions randomly. Advanced algorithms to create reliability across tests without over standardization fail. Over standardization can be cracked through excessive preparation. Besides, the probability of question not repeating is greater than zero. Information sharing amongst test takers in India is very high leading to leaked questions. Offline test requires eLitmus to develop only 18-20 question papers per year, with no test or question ever repeated. Moreover in Indian context, the infrastructure for online test often crumbles midway between the test. Additionally third party environments (like college networks), are prone to being hacked. This enables a person to remotely answer the test for a test taker sitting in front of the machine.
- Ability to serve a diverse set of customers
eLitmus has identified 7 major skills and 2 sub skills. Every question is mapped to one of these skills. Based on the job description and historical information about the company, a different weight is assigned to each skill and the score customized to the company's precise requirement. It's a little like how just over a 100 elements make billions of compounds.
- Handicap based negative marking and score interpretation
This has been developed by eLitmus with over 10 person-years of R&D. It is an empirical approach that leverages the performance feedback of companies. While the exact mechanics are proprietary to eLitmus, a couple of notable features follow. First, negative marking based on resources utilized (similar to Duckworth Lewis methodology in cricket) and the accuracy of wrong answers. For example a student who gets 4 wrong answers out of 30 attempts is penalized higher for each wrong answers compared to a student who gets 4 wrong anwers out of 40 attempts. Second, every question has close wrong answers and irrelevant wrong answers. For example a question like “What is the capital of India?” could have choices as Delhi, New Delhi, Mumbai and Bangalore. A person marking Delhi as an answer is treated differently as compared to a person marking Mumbai or Bangalore.
- Ability to create gradient in the top quartile of test-takers by using handicap-based negative marking and a highly-researched test form design.
Tests have an inherent bias towards creating gradient at the higher end of the talent pool, thereby giving inaccurate results. The normal curve figure along side is self explanatory. The table below has data gathered from results of a leading MBA entrance test in India, primarily designed to cater to the needs of the very top B Schools in India. The above test due to its reputation is being used by several other B Schools to offer admissions. It is evident that it is difficult to differentiate among the talent pool not at the very top end of the performance.
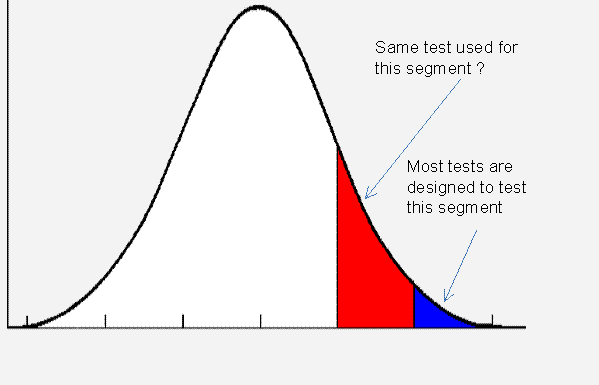
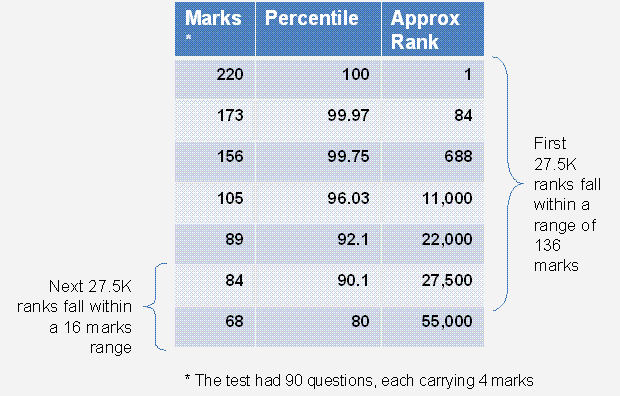
All tests by default have this inherent bias of creating differentiation at the top end.
A decade ago, the top 2% of talent pool sufficed to fill up all positions in companies or seats in leading MBA colleges. Lot of engineers from leading institutes used to find it difficult to find jobs. Today the story is in stark contrast. The top 25% of the talent pool is proving inadequate viz a viz the demand. The theory and science behind design effective tests is yet to wake up to this reality and hence some of the best tests designed by practitioners of psychometric principles produce below average employees or non performing students.
- High preparedness of the candidates
Typically test format or questions are extremely predictable for a company. A candidate gets a long time to prepare for such tests and clear it with ease. Even the IITs recently identified the long, systematic 'test' preparation by candidates as a reason for the falling quality of their in-take.